How to compute modular exponentiation c = xe mod n efficiently, especially when exponentiation part e is large?
A better algorithm is exponentiation by squaring [1], we can express e in binary representation:
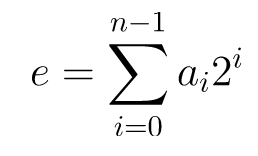
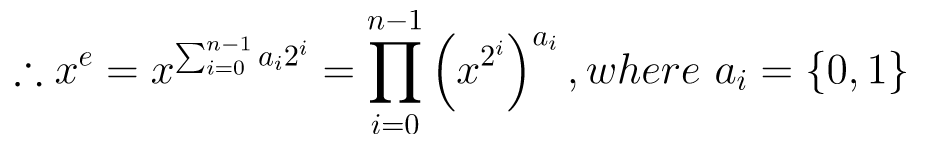
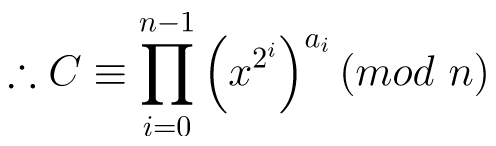
/// Modular Exponentiation /// Inputs: x, e, n 128-bit integer /// Output: x^e mod n (128-bit integer) uint128_t modexp(uint128_t x, uint128_t e, uint128_t n) { uint128_t base = x; x = 1; while (e) { if (e & 0x1) { uint256_t xb = uint256_t::mul(x, base); x = xb.mod(n); } uint256_t xb = uint256_t::mul(base, base); base = xb.mod(n); e >>= 1; } return x; }And modulo:
uint128_t mod(const uint128_t b) const { uint128_t r = 0; for (uint16_t x = bits(); x > 0; x--) { r <<= 1; if (x > 128) { if ((high >> (x - 1U - 128)) & 1) ++r; } else { if ((low >> (x - 1)) & 1) ++r; } if (r >= b) r -= b; } return r; }Even though the mod only use bit operations, but it is actually a very expensive operation, because of the for loop. Better algorithm? In modexp function, we compute double width product x*base, and base*base, then find their smallest nonnegative representation by performing a mod.
base*base ≡ c (mod n)
x*base ≡ d (mod n)
The idea is, we can use different equivalence class for x and base, such that divide and modulo in these classes become very cheap [2][3]. On the computer system, we choose R = 2k and R > n, transform x and base into Montgomery representation by x*R mod n, base*R mod n, such that modulo R just discards high bits, divide R just shifts bits right [2][3].
Let's look at the code, the code framework is similar to modexp.
/// Inputs: x, e 128-bit integer /// Output: x^e mod n (128-bit integer) /// /// n is initialized in constructor uint128_t montModExp(uint128_t x, uint128_t e) { uint128_t mX = toMontSpace(1); uint128_t mBase = toMontSpace(x); while (e) { if (e & 0x1) mX = montMul(mX, mBase); mBase = montMul(mBase, mBase); e >>= 1; } return montMul(mX, 1); }First, we transform x and base into Montgomery representation.
This is a 128-bit integer implementation, so we choose R = 2128
/// Transform x to Montgomery Representation. /// Inputs: x (128-bit integer) /// Output: c (128-bit integer) = x * R mod n /// /// R = 2^128 in 128-bit integer implementation. uint128_t toMontSpace(uint128_t x) { x %= N; for (int i = 0; i < 128; i++) { x <<= 1; if (x >= N) x -= N; } return x; }Then we perform Montgomery multiplication xR (mod n) * baseR (mod n), and (baseR)2 (mod n),
/// Compute Montgomery multiplication. /// cR = aR * bR * R^-1 (mod n) /// /// mA = aR, mB = bR. mA and mB are in Montgomery space. (128-bit integer) uint128_t montMul(uint128_t mA, uint128_t mB) { return reduce(uint256_t::mul(mA, mB)); }Note:
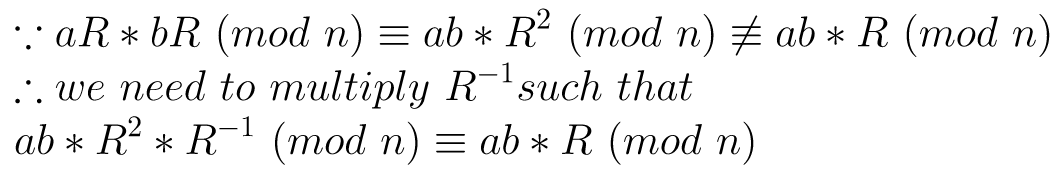
This is a critical step and is known as Montgomery reduction. [4][3][5][2]
Let's see the mathematics and how to implement it.
Let T = (aR mod n)(bR mod n)
The idea is, add kn to T such that T + kn ≡ 0 (mod R) , therefor TR-1 ≡ (T + kn)/R (mod n) [2][3]
Why it is correct? If we just multiply two numbers without (mod n) for each number:
(aR)(bR) / R = abR, then perform (mod R), we can have correct result abR (mod n)
But we can't directly T / R, because after modulo operation, T is not divisible by R.
However, T + kn is divisible by R, and T + kn ≡ T (mod n)
So we can add kn to T, such that T + kn ≡ 0 (mod R), then we can directly divide R from it.

How to find k? The algorithm [4][3]:
function reduce(T): k = (T mod R) * n' mod R a = (T - k * n) / R if a < 0: a += n return a

[cp-algorithm:montgomery_multiplication]
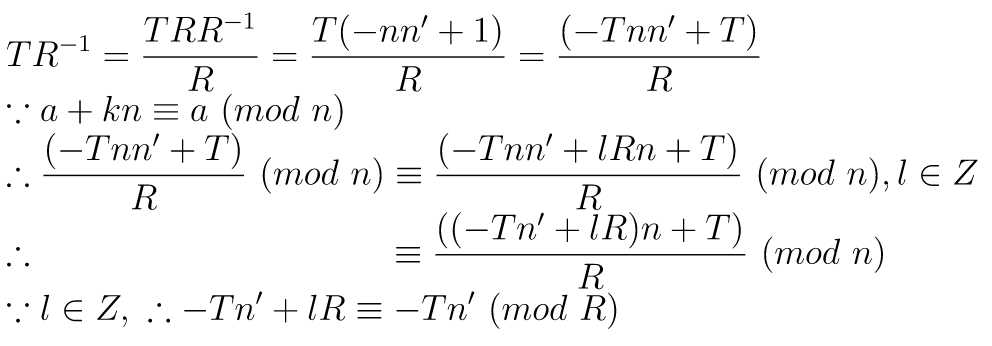
Note: ∵ R = 2k , in our implementation, it is R = 2128,
∴ (mod R) = drop bits >= 128 bits,
(div R) = shift right 128 bits, in other words, drop lower 128 bits
They are cheap on the computer system.
Also a = [-n, n-1]
/// Compute Montgomery Reduction. /// cR = xR^2 * R^-1 (mod n) /// /// Algorithm: /// q = (xR^2 mod R) * n' mod R /// a = (xR^2 + q * n) / R /// if a >= n: /// a -= n /// return a uint128_t reduce(uint256_t xR2) { uint128_t q = xR2.low * Ninv; int128_t a = xR2.high - uint256_t::mul(q, N).high; if (a < 0) a += N; return a; }We can also think in this way (wiki Montgomery reduction):
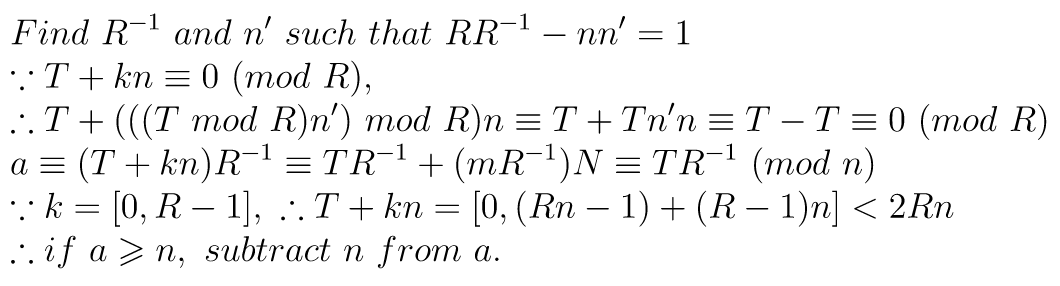
Next question is how to find n' (that is: inverse of n, such that nn' ≡ 1 (mod R) )?
There is a fast inverse trick:
(directly copy from: https://cp-algorithms.com/algebra/montgomery_multiplication.html#toc-tgt-2)
Proof: Let ax = 1 + m * 2k

// Compute N^-1 s.t. N * N^-1 ≡ 1 (mod R) // Fast inverse trick: // a * x ≡ 1 (mod 2^k) => a * x * (2 - a * x) ≡ 1 (mod 2^(2k)) // // Ninv = 1, // (1) N * Ninv ≡ 1 (mod 2^1) => N * Ninv * (2 - N * Ninv) (mod 2^2) // Update Ninv = Ninv * (2 - N * Ninv) // (2) N * Ninv ≡ 1 (mod 2^2) => N * Ninv * (2 - N * Ninv) (mod 2^4) // Update Ninv = Ninv * (2 - N * Ninv) // (3) ... // (7) N * Ninv ≡ 1 (mod 2^64) => N * Ninv * (2 - N * Ninv) (mod 2^128) Ninv = 1; for (int i = 0; i < 7; ++i) Ninv = Ninv * (2 - N * Ninv);We finished the Montgomery exponentiation implementation.
But the transformation of a number to Montgomery representation is too slow, actually we can optimize it by the fact:

The algorithm for computing R2 mod n:
R2 = -N % N;
for (int i = 0; i < 4; i++) {
R2 <<= 1;
if (R2 >= N)
R2 -= N;
}
for (int i = 0; i < 5; i++) {
R2 = montMul(R2, R2);
}
Note -N % N ≡ R - N ≡ R (mod N).Then modify our montModExp:
/// Compute: c = x^e mod n /// /// x, e, and c are 128-bit integers. /// n and r^2 is initialized in constructor uint128_t montModExp(uint128_t x, uint128_t e) { // Result x in Montgomery Space uint128_t mX = montMul(1, R2); // Transform x to Montgomery Space as base // mBase = x * r^2 * r^-1 (mod N) uint128_t mBase = montMul(x, R2); while (e) { if (e & 0x1) mX = montMul(mX, mBase); mBase = montMul(mBase, mBase); e >>= 1; } // Transform x from Montgomery Space to Normal Space. return montMul(mX, 1); }Done! (=゚ω゚)ノ
Performance Comparison:
- Compile Flags: -std=c++11 -Wall -O3 -DNDEBUG
- Machine: i7-4770HQ CPU @ 2.20GHz
- n = 0x9e40fd675571e0af74d65da4ea541cf
x = 0xfbeab553608bdf65b2ab09bb910317f9
e = 0x172a202e867b11779604827082342863 - Test loop: 10000
- modexp takes 3133.34 msec
- Montgomery exponential: takes 18.7284 msec.
167 times faster than modexp.
https://github.com/cycheng/coding-for-fun/blob/master/crypto/montgomery.cpp
References:
[1] https://en.wikipedia.org/wiki/Modular_arithmetic
[2] (Traditional Chinese) https://ee.ntu.edu.tw/upload/hischool/doc/2011.07.pdf
[3] https://en.wikipedia.org/wiki/Montgomery_modular_multiplication
[4] https://cp-algorithms.com/algebra/montgomery_multiplication.html
[5] https://cryptography.fandom.com/wiki/Montgomery_reduction
Good Tools:
[1] Big number calculator https://www.boxentriq.com/code-breaking/big-number-calculator
[2] Online LaTeX editor https://www.codecogs.com/latex/eqneditor.php