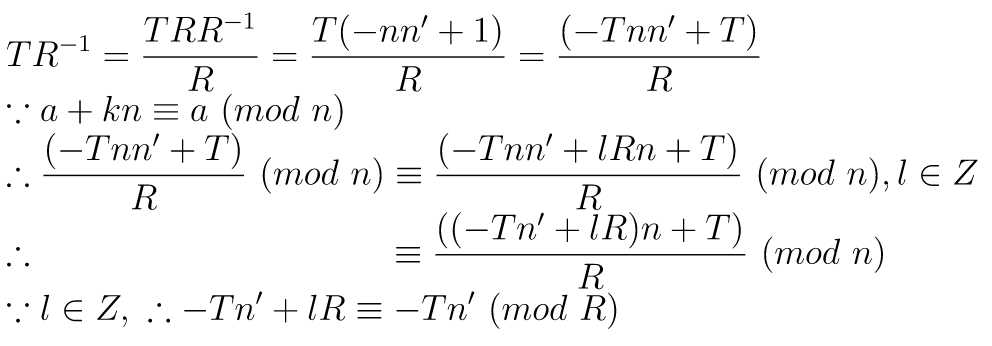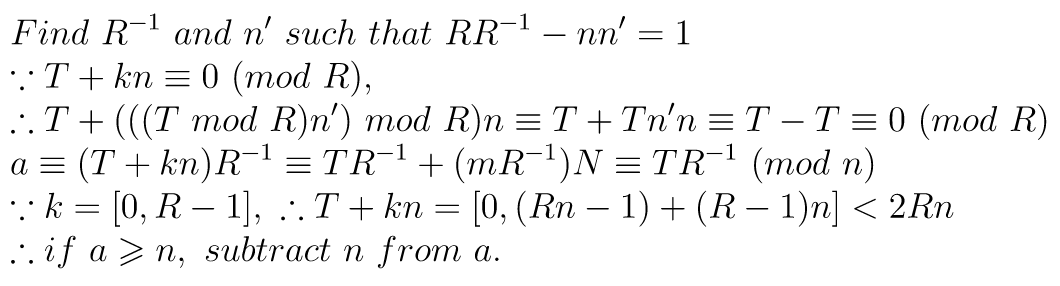- Pass lvalue to rvalue?
- rvalue reference is an lvalue?
- When do we need a .template construct?
Pass lvalue to rvalue?
https://stackoverflow.com/questions/14667921/pass-lvalue-to-rvaluevoid enqueue(const T& item) { std::unique_lock<std::mutex> lock(m); this->push(item); this->data_available = true; cv.notify_one(); } void enqueue(T&& item) { std::unique_lock<std::mutex> lock(m); this->push(std::move(item)); this->data_available = true; cv.notify_one(); }How to combine enqueue into one function?
template <class U> void enqueue(U&& item) { std::unique_lock<std::mutex> lock(m); this->push(std::forward<U>(item)); this->data_available = true; cv.notify_one(); }Howard Hinnant: "If you pass an lvalue T to enqueue, U will deduce to T&, and the forward will pass it along as an lvalue, and you'll get the copy behavior you want. If you pass an rvalue T to enqueue, U will deduce to T, and the forward will pass it along as an rvalue, and you'll get the move behavior you want."
q.enqueue(1); // ok q.enqueue(1.0); // 1.0 -> (int) 1, ok
// Only allow U and T are the same type. template <class U> typename std::enable_if< std::is_same<typename std::decay<U>::type, T>::value >::type enqueue(U&& item) { .. }
// assume q uses int type. q.enqueue(1.0); // 1.0 is double, xThe other approach provided by ipc:
void enqueue(const T& item) { enqueue_emplace(item); } void enqueue(T&& item) { enqueue_emplace(std::move(item)); } template <typename... Args> void enqueue_emplace(Args&&... args) { std::unique_lock<std::mutex> lock(m); this->emplace(std::forward<Args>(args)...); this->data_available = true; cv.notify_one(); }
rvalue reference is an lvalue?
https://www.cprogramming.com/c++11/rvalue-references-and-move-semantics-in-c++11.htmlstruct MetaData { // copy constructor MetaData (const MetaData& other) { .. } // move constructor MetaData (MetaData&& other) { .. } }; class ArrayWrapper { public: // move constructor ArrayWrapper (ArrayWrapper&& other) : _metadata( other._metadata ) {} // copy constructor ArrayWrapper (const ArrayWrapper& other) : _metadata( other._metadata ) {} private: MetaData _metadata; };"ArrayWrapper (ArrayWrapper&& other) : _metadata( other._metadata ) {}"
"the value of other in the move constructor--it's an rvalue reference. But an rvalue reference is not, in fact, an rvalue. It's an lvalue, and so the copy constructor is called, not the move constructor."
"In the context where the rvalue expression was evaluated, the temporary object really is over and done with. But in our constructor, the object has a name; it will be alive for the entire duration of our function."
ArrayWrapper (ArrayWrapper&& other) : _metadata( std::move(other._metadata) ) {}use std::move. std::move(T&& arg) returns an rvalue reference to arg.
https://stackoverflow.com/questions/1116641/is-returning-by-rvalue-reference-more-efficient
struct Beta { Beta_ab ab; Beta_ab const& getAB() const& { return ab; } Beta_ab && getAB() && { return move(ab); } }; // the second function is invoked on rvalue temporaries, // making the following move, instead of copy Beta_ab ab = Beta().getAB();
When do we need a .template construct?
https://stackoverflow.com/questions/3499101/when-do-we-need-a-template-constructtemplate< class T > void f( T &x ) { x->variable < T::constant < 3 >; }Ambiguity:
- Case 1:
(T::constant < 3) => bool
x->variable<bool>; - Case 2:
T::constant<3> => value
x->variable < value;
Solutions
- Case 1: x->template variable < T::constant < 3 >;
- Case 2: x->variable < T::template constant < 3 >;